One-class Classification (Ep 1/2)

Outliers หรือ Anomalies คือ Data Points ส่วนน้อย ที่ไม่สอดคล้องกับข้อมูลที่มีอยู่
- การระบุค่า Outliers หรือ Anomalies ในข้อมูล เรียกว่า "Anomaly Detection" และ
สาขาย่อยของ Machine Learning ที่เน้นไปที่ปัญหานี้ เรียกว่า One-class Classification - ซึ่งเป็น Unsupervised Learning Algorithms ที่พยายามสร้าง Model
ของข้อมูลตัวอย่างที่เป็นปกติ (Normal Samples) เพื่อจำแนก Sample ที่เข้ามาใหม่ว่า
เป็น ค่าปกติ (Normal) หรือ ผิดปกติ (Anomaly) - One-class Algorithm ใช้สำหรับ Binary Classification ที่เป็น Imbalance Datasets
- เทคนิคเหล่านี้ สามารถ Fit กับ Input Samples ที่เป็น Class ส่วนใหญ่ (Majority Class) ในชุดข้อมูลการ Train จากนั้นจึงประเมิน Model กับข้อมูล Test
- แม้ว่าจะไม่ได้ออกแบบมาสำหรับปัญหาประเภทนี้โดยตรง แต่ One-class Algorithms
ก็สามารถนำไปประยุกต์ใช้ในการจำแนกข้อมูลที่เป็น Imbalance
ใน Blog นี้ จะพูดถึง One-class Classification ซึ่งเป็นการนำ ML ไปใช้ในการตรวจจับค่าผิดปกติ (Anomaly Detection) การนำ One-class Classification ไปประยุกต์ใช้กับปัญหาข้อมูล Imbalance ที่มีการกระจายของ Class แบบ Skewed การ Train และ Evaluate Model โดยใช้ One-class Classification Algorithms เช่น SVM, Isolated Forest, Elliptic Envelop และ Local Outlier Factor
โดยแบ่งเนื้อหาเป็น 5 ส่วน คือ
- สร้าง Imbalance Dataset สำหรับ One-class Classification
- One-class Classification โดยใช้ SVM
- Isolated Forest
- Minimum Covariance Determinant
- Local Outlier Factor
- สร้าง Imbalance Dataset สำหรับ One-class Classification
- Outliers คือ สิ่งที่เกิดขึ้นน้อย และ ไม่ใช่ค่าปกติ
- สิ่งที่เกิดขึ้นน้อย คือ มีความถี่ต่ำ เมื่อเทียบกับ Non-outlier Data (Inliers)
ไม่ใช่ค่าปกติ คือ ไม่สามารถถูก Fit ได้กับการกระจายค่าปกติ - การมีอยู่ของ Outliers ก็ทำให้เกิดปัญหา เช่น ค่า Outliers จะอยู่ไกลจากค่าอื่น
หากพิจารณาจาก Summary Statistics เช่น Mean, Variance ก็ทำให้ผิดเพี้ยนไป - ในการสร้าง ML Model อาจต้องมีการ Remove Outliers ออกก่อนในขั้นตอนการทำ Data Preparation
- กระบวนการในการระบุ Outliers ใน Dataset เรียกว่า Anomaly Detection ซึ่ง Outliers คือ Anomalies และ ส่วนที่เหลือ คือ Normal (ค่าปกติ)
- ในทาง ML วิธีการแก้ปัญหานี้ คือ การใช้ One-class Classification (เขียนย่อว่า OCC) ใช้ในการสร้าง Model สำหรับ Normal Data และ ทำนายว่า Data Point ที่เข้ามาใหม่ คือ ค่าปกติ หรือ ค่าที่ผิดปกติ
(Outlier/Anomaly)
One-class Classifiers ถูก Fit กับ Training Data ซึ่ง Sample จะมีเพียง Normal Class
หรือ One Class Classification สามารถใช้สำหรับ Binary (Imbalanced) Classification เช่น Class 0 (Normal / Inlier) และ Class 1 (Anomaly / Outlier)
โดยปกติแล้ว One-class Classification ถูกออกแบบมาสำหรับในกรณีที่ Class 1 (Outlier)
ไม่มี Patterns ที่แน่ชัด Algorithm จะเรียนรู้จาก Class Boundary เหมาะกับกรณีที่ Class 1 มีจำนวนน้อย ซึ่งจะไม่มีประสิทธิภาพเมื่อรวมเข้าไป Train สำหรับการสร้าง Model เช่น จำนวหลักหลายสิบ หรือ อาจเป็นกรณีที่ Class 1 ไม่สามารถเก็บข้อมูลได้ การนำ One-class Classification ไปประยุกต์ใช้กับ Imbalance Classification ถือเป็นเรื่องไม่ปกติ อาจะเกิดผลกระทบได้ในบางกรณี
ข้อเสียของแนวทางนี้ คือ Data Points ที่เป็น Outliers จะไม่ถูกนำมาใช้ในการ Train ข้อแนะนำ คือ สามารถทดลองในรูปแบบ Inverse Modeling (พิจารณากลับ Class กัน) เป็นคู่ขนานไปได้ นอกจากนี้ ยังสามารถใช้ Ensemble Learning ซึ่ง Models
ถูกสร้างจาก Training Datasets ในแนวทางที่แตกต่างกัน
Scikit-Learn Library มี One-class Classification Algorithms เช่น One-class SVM, Isolated Forest, Elliptic Envelop, Local Outlier Factor
ตัวอย่าง สร้างข้อมูลสำหรับทำ Binary Classification โดยใช้ฟังก์ชัน make_classification() ใน Scikit-learn เพื่อสร้างตัวอย่าง 10,000 ตัวอย่างโดยมี 10 ตัวอย่างใน Minority Class และ 9,990 ตัวอย่างใน Majority Class หรือ 0.1% เทียบกับ 99.9% หรือ 1:1,000
# Simulate the dataset and visualize the data
from collections import Counter
from sklearn.datasets import make_classification
from matplotlib import pyplot
from numpy import where
# Define the dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.999], flip_y=0, random_state=4)
# Summarize the class distribution
counter = Counter(y)
print(counter)
# Visualiza by using a scatter plot
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()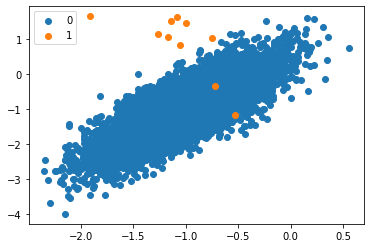
- Label ของ Class ส่วนมาก แสดงด้วยสีน้ำเงิน และ มีเพียงไม่กี่ Data Points
แสดงด้วยสีส้ม เป็น Imbalance Dataset ที่มีเพียงไม่กี่ Data Point เป็น Class 1 ซึ่งไม่มีรูปแบบที่ชัดเจน สามารถทดลองใช้ One-class Classification ได้
- One-class Classification โดยใช้ SVM
SVM (Support Vector Machine) ถูกพัฒนาขึ้นมาสำหรับการทำ Binary Classification และ สามารถใช้ในการทำ One-class Classification ได้
หากใช้สำหรับ Imbalance Dataset อาจทำการ Evaluate ระหว่าง Standard SVM และ
Weighted SVMก ก่อนที่จะทำการ Test สำหรับ One-class เมื่อสร้าง Model แบบ One-class Algorithm จะจับความหนาแน่นของ Class ส่วนใหญ่ และ Classify Data Point ที่อยู่ต่างไปมากๆ เป็น Outlier เรียกว่า One-Class SVM
สามารถเรียกใช้ One-class SVM จาก Scikit-Learn ได้
ความแตกต่างจาก Standard SVM คือ จะ Fit ในรูปแบบ Unsupervised ไม่มี Hyper-
parameters ปกติ ที่ใช้ใน SVM เข่น C (Margin) แต่จะมี Hyper-parameter “nu” ที่ใช้ควบคุม Sensitivity ของ Support Vector โดยควรจะปรับไว้ตามสัดส่วนของ Outlier เช่น 0.01%
- กำหนด Outlier Detection Model
model = OneClassSVM(gamma='scale', nu=0.01)สามารถทำการทดลองได้ทั้ง 2 แบบ ในการใช้ Model ในการ Fit ทุก Data Points
หรือเฉพาะ Data Points ที่เป็น Majority Class ในกรณีที่ทำการ Fit เฉพาะ Majority Class
ดังนี้
- ทำการ Fit ที่ Majority Class
trainX = trainX[trainy==0]
model.fit(trainX)หลังจาก Fit แล้ว สามารถทดลองใช้ Model ในการระบุ Outliers จาก New Data ได้
เรียกใช้ predict() กรณีที่ Output เป็น +1 คือ Normal หรือ Inlier หาก Output เป็น -1 คือ
Anomaly หรือ Outlier
- การ Detect Outliers ใน Test Set
yhat = model.predict(testX)- หากต้องการประเมินประสิทธิภาพ Model (ในที่นี้คือ Binary Classifier) ทำการเปลี่ยน
Label ของ Test Data จาก 0 เป็น +1 และ จาก +1 เป็น -1
testy[testy == 1] = -1
testy[testy == 0] = 1- สามารถใช้ Metrics ในการประเมิน เช่น Precision, Recall หรือ F1 score (Harmonic mean ของ Precision และ Recall) ทำการหา Score ดังนี้
score = f1_score(testy, yhat, pos_label=-1)
print('F1 Score: %.3f' % score)👨🏻💻 Code ทั้งหมด
- โดยใช้ One-class SVM ในการสร้าง Classification Model และจากนั้นทำการประเมินประสิทธิภาพของ Model
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.svm import OneClassSVM
# Define the dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.999], flip_y=0, random_state=4)
# Split train/test sets
trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2, stratify=y)
# Define an outlier detection model
model = OneClassSVM(gamma='scale', nu=0.01)
# Fit on majority class
trainX = trainX[trainy==0]
model.fit(trainX)
# Detect outliers in the test set
yhat = model.predict(testX)
# Change -> inliers 1, outliers -1
testy[testy == 1] = -1
testy[testy == 0] = 1
# Evaluate the model
score = f1_score(testy, yhat, pos_label=-1)
print('F1 Score: %.3f' % score)- จากการ Fit Data ที่เป็น Majority Class ใน Training Data ทำให้ Model สามารถใช้ในการ Classify ระหว่าง Inliers และ Outliers ใน Test Data ในกรณีนี้ ค่า F1 Score เท่ากับ 0.123
ยังมีต่อ Ep 2
******
ข้อมูลอ้างอิง - https://machinelearningmastery.com/one-class-classification-algorithms/