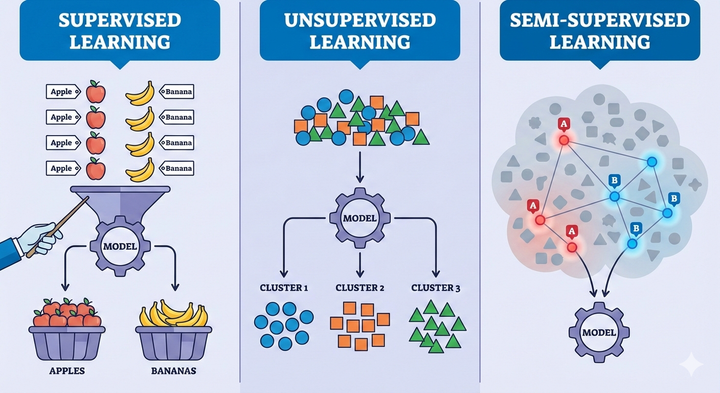
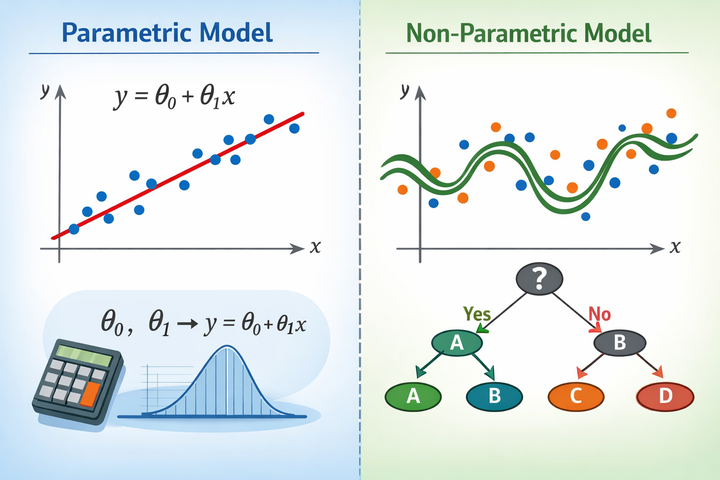
OVR vs OVO: ศึกสองแนวคิดของ Machine Learning

กลยุทธ์ One-vs-Rest (OvR) และ One-vs-One (OvO) เป็นวิธีการแปลงปัญหา Multi-class Classification ให้เป็นชุดของ Binary Classificationเพื่อใช้กับโมเดลที่รองรับแค่การจำแนก 2 Classes เช่น Logistic Regression, SVM เป็นต้น
1. One-vs-Rest (OvR)
แนวคิด: สร้างโมเดลหนึ่งตัวต่อหนึ่งคลาส โดยเปรียบเทียบ คลาสนั้นกับคลาสอื่นทั้งหมด
ถ้ามี K คลาส → จะได้ K โมเดล
ตัวอย่าง
- คลาส A vs (B, C, D)
- คลาส B vs (A, C, D)
- คลาส C vs (A, B, D)
การทำนาย: เลือกโมเดลที่ให้ probability สูงสุด หรือ score สูงสุด
ข้อดี: ใช้ง่ายและเร็วกว่า OvO เมื่อจำนวนคลาสเยอะ
ข้อเสีย: อาจมีปัญหา imbalance เพราะกลุ่ม "Rest" ใหญ่มากo โมเดลต้องแยกหลายคลาสพร้อมกัน
2. One-vs-One (OvO)
แนวคิด: สร้างโมเดลสำหรับ ทุกคู่ของคลาส
ถ้ามี K คลาส → จะได้ K(K-1)/2 โมเดล
ตัวอย่าง
- A vs B
- A vs C
- B vs C
การทำนาย: ใช้ Voting จากทุกโมเดลคู่
ข้อดี: แต่ละโมเดลง่ายกว่า เพราะแยกแค่ 2 คลาส
ข้อเสีย: จำนวนโมเดลเยอะมากเมื่อคลาสเยอะ → ใช้เวลาและทรัพยากรสูง
สรุปการเลือกใช้
- OvR เหมาะกับ จำนวนคลาสเยอะ, โมเดลที่เทรนเร็ว
- OvO เหมาะกับ โมเดลที่เทรนช้าแต่แม่นยำ เช่น SVM, และจำนวนคลาสไม่มาก
ตารางเปรียบเทียบ One-vs-Rest (OvR) และOne-vs-One (OvO):
คุณสมบัติ | One-vs-Rest (OvR) | One-vs-One (OvO) |
แนวคิด | สร้างโมเดลหนึ่งตัวต่อหนึ่งคลาส เทียบกับคลาสอื่นทั้งหมด | สร้างโมเดลสำหรับทุกคู่ของคลาส |
จำนวนโมเดล | K โมเดล (ถ้ามี K คลาส) | K(K-1)/2 โมเดล (ถ้ามี K คลาส) |
ความซับซ้อน | น้อยกว่า OvO | สูงกว่า OvR |
การทำนาย | เลือกโมเดลที่ให้ probability สูงสุด | ใช้การโหวตจากทุกโมเดลคู่ |
ข้อดี | เทรนเร็วกว่าเมื่อคลาสเยอะ | โมเดลง่ายกว่าเพราะแยกแค่ 2 คลาส |
ข้อเสีย | อาจมีปัญหา imbalance ในกลุ่ม Rest | จำนวนโมเดลเยอะ ใช้ทรัพยากรสูง |
เหมาะกับ | จำนวนคลาสเยอะ, โมเดลเทรนเร็ว | จำนวนคลาสน้อย, โมเดลแม่นยำ เช่น SVM |