DBSCAN Clustering คือ อะไร

ย่อจาก Density- Based Spatial Clustering of Applications with Noise
ถือเป็น Machine Learning ประเภท Unsupervised Learning ใช้ในการจัด Cluster
เป็น Density-based Clustering จัด Cluster โดยพิจารณาจากบริเวณที่มีความหนาแน่น โดยบริเวณที่มีความหนาแน่นน้อยอาจถูกพิจารณาเป็น Noise
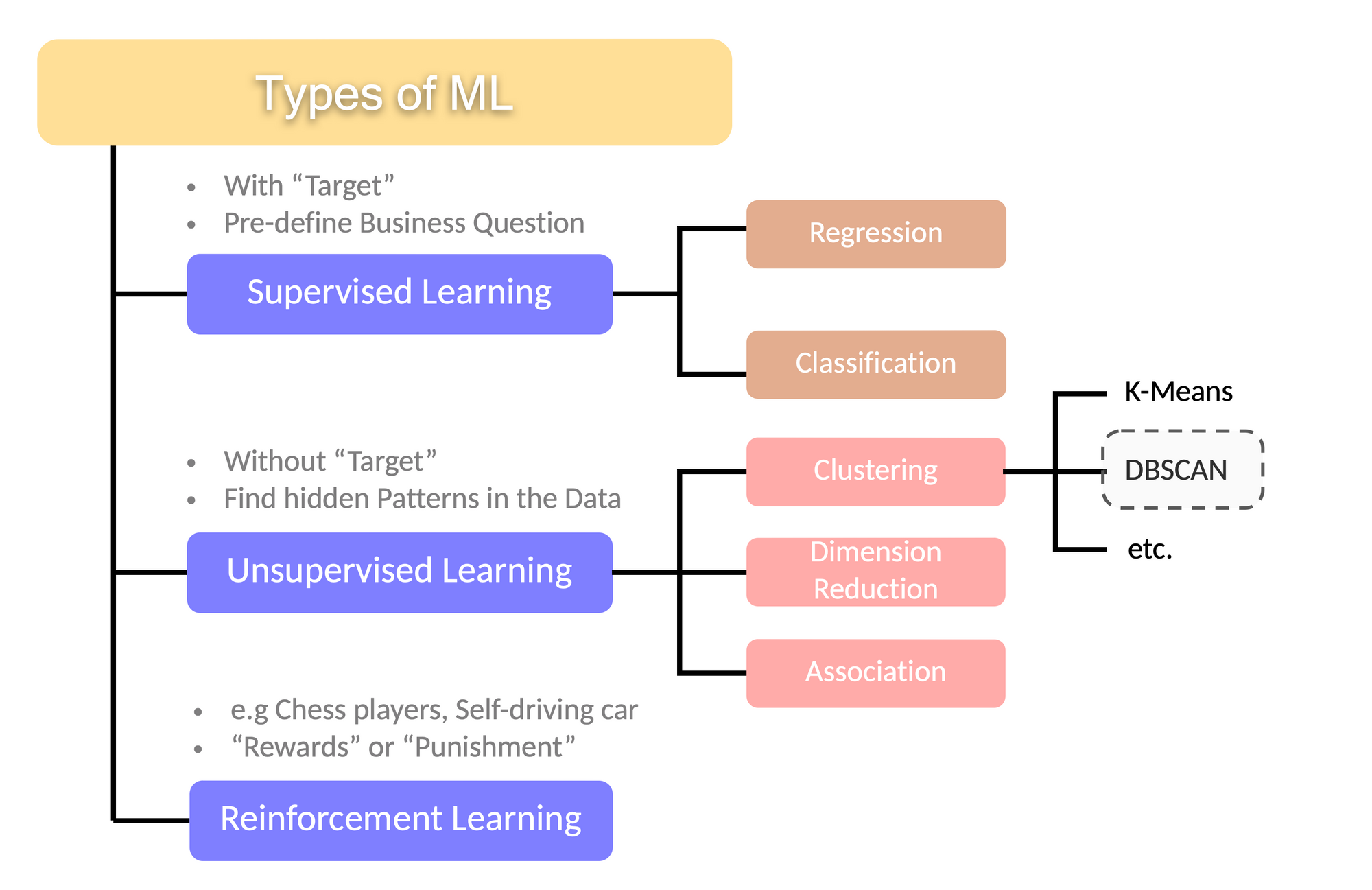
🟢 ข้อดี
- รูปร่างของ Cluster มีความยืดหยุ่น มากกว่า K-Means (K-Means จะทำบนสมมติฐานของ Cluster ทรงกลม เนื่องจากจัด Cluster โดยใช้ระยะทาง)
- การจัดการกับ Noise สามารถระบุข้อมูลที่เป็น Outliers และพิจารณา Data Points เหล่านั้นเป็น Noise ได้
- ไม่ต้องกำหนดจำนวน Cluster ก่อน การใช้งาน DBSCAN ไม่จำเป็นต้องระบุจำนวน Cluster ก่อนล่วงหน้า แตกต่างกับ K-Means
🔴 ข้อเสีย
- ความยากกับความหนาแน่นที่แตกต่างกัน ประสบปัญหาเมื่อ Clusters มีความหนาแน่นต่างกันอย่างมีนัยสำคัญ
- Border Points จุด (Data Point) หนึ่ง สามารถถูกพิจารณาอยู่ใน 2 Clusters ได้ ทำให้จุดที่อยู่บริเวณ Border ไม่มีความชัดเจน
- ความไวของพารามิเตอร์ (Sensitivity) ผลลัพธ์สามารถแตกต่างกันไปตาม Distance Parameter (Epsilon) และ Minimum Points
Applications
- Spatial Data Analysis สามารถใช้ Identify พื้นที่ที่มีความหนาแน่นสูง เช่น ความหนาแน่นของประชากรจาก Geographical Data
- Anomaly Detection ตัวอย่างของข้อมูล Credit Card Transaction สามารใช้ในการ Identify Pattern ที่ผิดปกติได้ ใช้ในการตรวจจับการฉ้อโกง (Fraud)
- Image Segmentation แยกระหว่าง Object (foreground) และ Background ในรูปภาพ
ตัวอย่าง Python Code 👨🏻💻 โดยใช้ Scikit Learn Library
ใช้ DBSCAN Algorithm
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# Create Data Points
data, label = make_moons(n_samples=500, noise=0.05, random_state=0)
# Using DBSCAN Algorithm
dbscan = DBSCAN(eps=0.3, min_samples=5)
clusters = dbscan.fit_predict(data)
# Visualizing Result
plt.scatter(data[:,0], data[:,1], c=clusters)
plt.title("DBSCAN Clustering Result")
plt.show()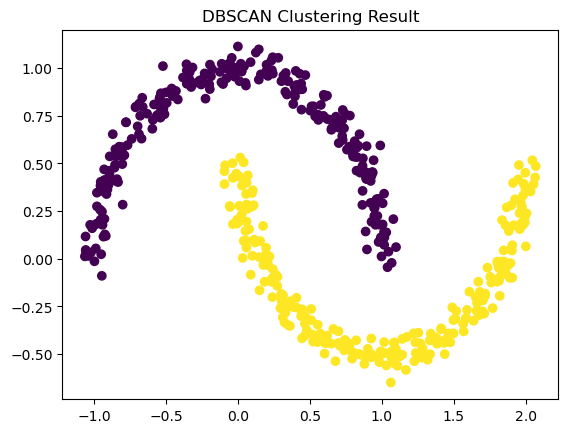
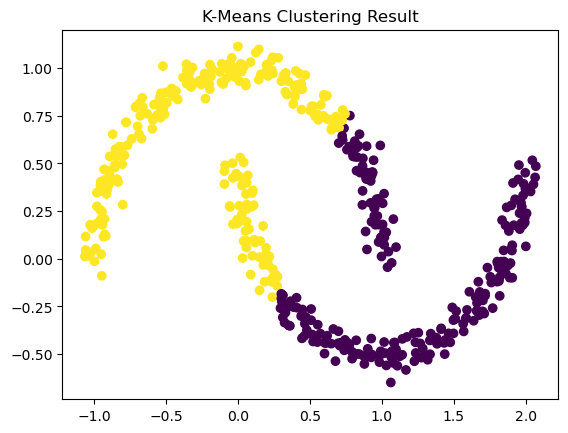
กรณีใช้ K-Means Algorithms ผลลัพธ์จากการ Cluster จะไม่มีประสิทธิภาพสำหรับ Dataset ชุดนี้ ❌
from sklearn.cluster import KMeans
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# Create Data Points
data, label = make_moons(n_samples=500, noise=0.05, random_state=0)
#Using K-Means Algorithms
kmeans = KMeans(n_clusters=2, random_state=0, n_init="auto").fit(data)
# Visualizing Result
plt.scatter(data[:,0], data[:,1], c=kmeans.labels_)
plt.title("K-Means Clustering Result")
plt.show()
******
อ่านเพิ่มเติม Pros & Cons ของ Machine Learning Algorithms ที่นิยมใช้
******
ข้อมูลอ้างอิง - Analytics Vidhya


