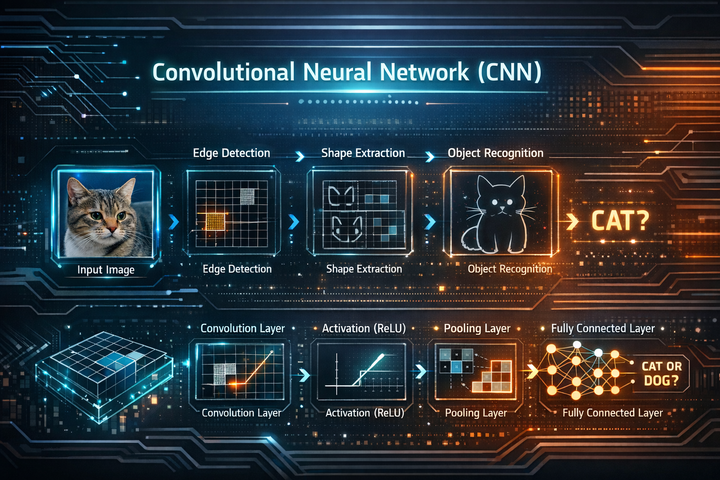
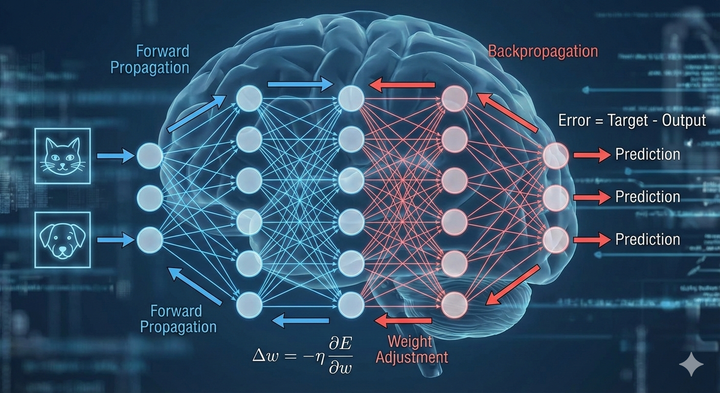
ปัญหาของ Deep Learning: Vanishing vs Exploding Gradients

Vanishing and Exploding Gradients เป็นปัญหาที่พบบ่อยตอนฝึก (train) Neural Networks (NN) โดยเฉพาะ Deep NN และ RNN ดังนี้
1. Vanishing Gradient
คือ Gradient มีค่าน้อยมาก ๆ ใกล้ศูนย์ → น้ำหนักชั้นต้น ๆ แทบไม่ถูกอัปเดต → โมเดล “เรียนไม่ไป”
เกิดขึ้นเพราะ
- ใช้ activation ที่ทำให้ Gradient เล็ก เช่น sigmoid, tanh
- โมเดลลึกมาก (หลาย layers)
- ใน RNN เมื่อย้อนเวลายาวๆ (long sequences)
ตัวอย่าง
- เหมือนเสียงกระซิบ ส่งต่อหลายคนที่เบาลงเรื่อยๆ พอถึงคนแรก เสียงเบามากจนแทบไม่ได้ยิน
ผลกระทบ
- ชั้นแรก ๆ ไม่เรียนรู้
- เทรนช้ามาก หรือ accuracy ไม่ดี
2. Exploding Gradient
คือ Gradient มีค่ามากผิดปกติ → น้ำหนักอัปเดตมากเกินไป → loss กระโดด, โมเดลพัง
เกิดขึ้นเพราะ
- น้ำหนักเริ่มต้นมากเกินไป
- ลึกมาก และคูณค่ากันซ้ำ ๆ
- RNN ที่มี sequence ยาว
ตัวอย่าง
- เหมือนตะโกนส่งต่อหลายคน เพิ่มความดังขึ้นเรื่อย ๆ จนหูแตก
ผลกระทบ
- Loss เป็น NaN / infinity
- Training ไม่เสถียร
3. วิธีแก้
แก้ Vanishing Gradient
- ใช้ ReLU / Leaky ReLU / GELU
- ใช้ Batch Normalization
- ใช้ Residual / Skip connections (ResNet)
- ใน RNN ใช้ LSTM / GRU
แก้ Exploding Gradient
- Gradient Clipping (นิยมมากใน RNN)
- ลด learning rate
- Weight initialization ที่เหมาะสม
- ใช้ Batch Normalization