NumPy & Pandas สำหรับผู้เริ่มต้นงาน Data Science (Ep.2/2)

อ่าน Ep.1/2 ที่นี่ -> https://www.nerd-data.com/numpy-pandas-ep1/
******
Pandas คือ อะไร?
Pandas สร้างขึ้นบน NumPy และมีประโยชน์สำหรับการจัดการชุดข้อมูล มีโครงสร้างข้อมูลหลักอยู่ 2 โครงสร้าง คือ Series และ Dataframe โดยที่ Series จะเป็นลำดับของค่า และ Dataframe จะเป็นตารางที่มีแถวและคอลัมน์ กล่าวอีกนัยหนึ่ง Series คือ คอลัมน์ของ Dataframe
การสร้าง Series และ Dataframe
สร้าง Series โดยใส่ List ลงใน Method ดังนี้
import pandas as pd
type_car = pd.Series(['Sedan','Sports'])
type_car0 Sedan
1 Sports
dtype: objectยังมีสร้าง Dataframe โดยใส่ Dictionary ของ Objects โดยที่ Keys คือ ชื่อคอลัมน์ และ Values ค่าของคอลัมน์นั้น ดังนี้
df = pd.DataFrame({'Price': [400000, 600000], 'Year': [2020, 2021]})
df Price Year
0 400000 2020
1 600000 2021สามารถดูประเภทของแต่ละคอลัมน์ได้ จะเห็นว่าแต่ละคอลัมน์เป็น Series
type(df.Price),type(df.Year)(pandas.core.series.Series, pandas.core.series.Series)สรุป Functions ต่างๆ
Pandas สามารถใช้ Import file csv ได้ แสดงตัวอย่างโดยใช้ข้อมูล Titanic Dataset ดาวน์โหลดได้จาก Internet (keyword -> titanic.csv) หรือ Download จาก ที่นี่
df = pd.read_csv('titanic.csv')
df.head()
Pandas ไม่เพียงแต่อ่าน file csv ได้เท่านั้น แต่ยังสามารถอ่าน file Excel, JSON, Parquet และ อื่นๆ สามารถดูรายละเอียดได้ ที่นี่
เพื่อที่จะได้เข้าใจข้อมูลแบบคร่าวๆ ตัวอย่างด้านบนแสดง 5 แถวแรกของ Dataframe เราสามารถแสดง 5 แถวสุดท้ายได้โดยใช้ df.tail()
df.tail()
สามารถทราบ Shape ของ Dataframe ได้โดย
df.shapeมี 891 แถว และ 12 คอลัมน์ สามารถดูชื่อคอลัมน์ได้โดย
df.columns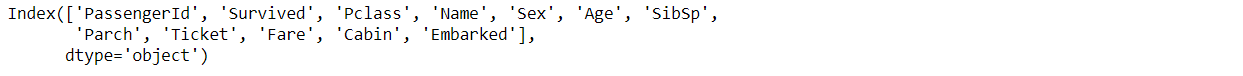
สามารถแสดง Info ของ Dataframe ได้ ดังนี้
df.info()
หากต้องการแสดงค่า Statistics ของแต่ละคอลัมน์ สามารถใช้ df.describe()
df.describe()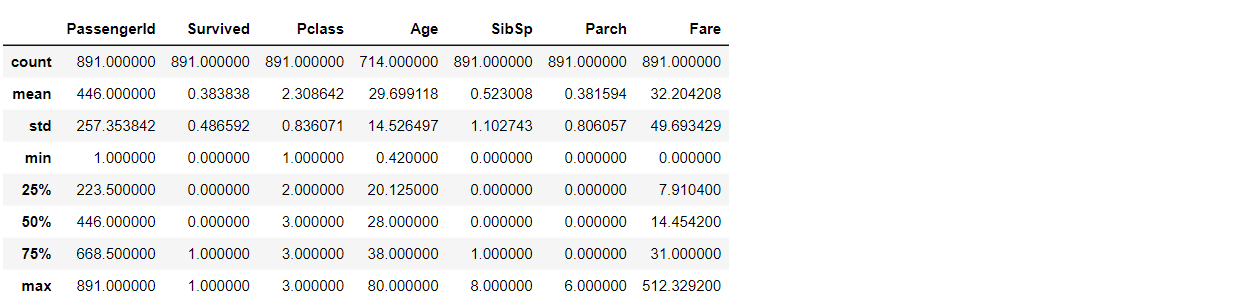
กรณีของ Categorical Column สามารถแสดงค่า Unique และ จำนวนค่าที่ Unique ได้
df['Sex'].unique(), df['Sex'].nunique()ค่า Output
(array(['male', 'female'], dtype=object), 2)เห็นว่ามีค่า male, female มีจำนวน Unique = 2
สามารถแสดงความถี่ของแต่ละค่า โดยใช้ value_counts()
df['Sex'].value_counts()
สามารถตรวจสอบ Missing Value ของแต่ละคอลัมน์ได้ ซึ่งใน Dataframe นี้ มี Missing Value ที่คอลัมน์ Age และ Cabin
df.isnull().sum()
Indexing และ Slicing
เช่นเดียวกับใน NumPy สามารถเลือกข้อมูลโดยอ้างอิงจาก Index มี 2 วิธีหลัก
- iloc เลือก Elements จาก Integer Position
- loc เลือก Elements จาก Labels หรือ Boolean Array
ในการเลือกแถวแรก iloc เป็นตัวเลือกที่ดีที่สุด
df.iloc[0]
หากต้องการเลือกคอลัมน์ที่ 3 สามารถทำได้ ดังนี้
df.iloc[:,2]
สามารถระบุ คอลัมน์ และ แถว ที่ต้องการได้
df.iloc[0:3,[0,1,2,4,5]]
อาจเป็นเรื่องง่ายกว่า แทนที่จะระบุด้วย Index แต่ใช้ชื่อคอลัมน์แทน ทำได้โดยใช้ loc
df.loc[0:3,['PassengerId','Survived','Pclass','Sex','Age']]
สามารถ Filter Dataframe โดยใช้ Condition ได้ เช่น
df[df['Sex']=='female']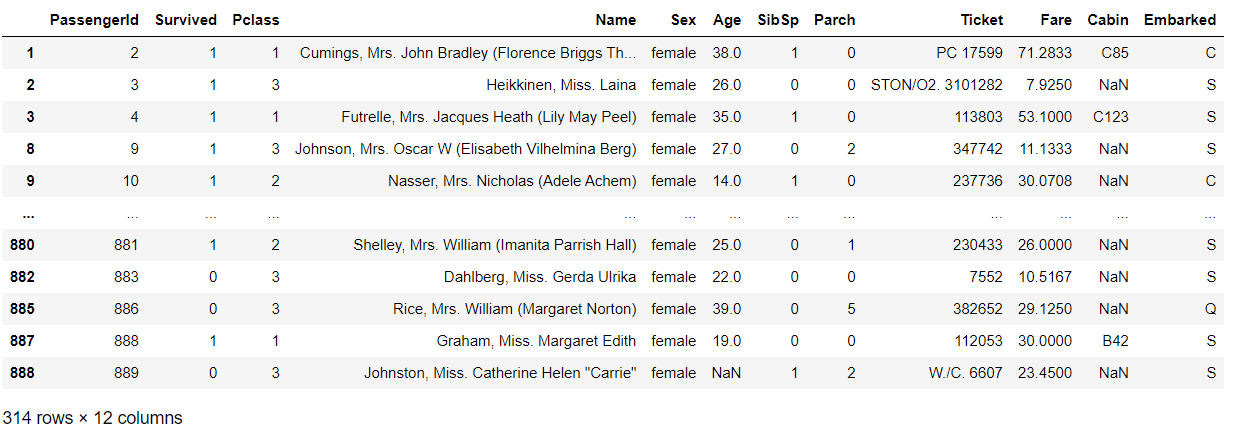
กรณีต้องการคอลัมน์เฉพาะ สามารถระบุได้ โดยใช้ loc
df.loc[df['Sex']=='female',['PassengerId','Age']]
สร้าง Variable ใหม่
การสร้าง Variable ใหม่ แสดงตัวอย่างการสร้าง Variable ใหม่ จาก Sex ไปเป็น Sex_Flag
df['Sex_Flag'] = df['Sex'].apply(lambda x: '1' if x=='male' else '0')
df[['Sex','Sex_Flag']].head()
หากมีเงื่อนไขมากกว่าหนึ่ง จะเป็นการดีกว่าหาก Map Value ด้วย Dictionary หรือ Map Method
dict_Pclass = {1:'first',2:'second',3:'third'}
df['Pclass_Flag'] = df['Pclass'].map(lambda x: dict_Pclass[x])
df[['Pclass','Pclass_Flag']].head()
Grouping และ Sorting
หากต้องการ Group Data โดยอ้างอิงจาก Categorical Column สามารถใช้ groupby
df.groupby('Pclass_Flag').agg({'Age':['median','max']})
ในแต่ละชั้นโดยสาร สามารถสังเกตค่ามัธยฐานของอายุผู้โดยสารได้ ผลลัพธ์นี้อาจมีการเรียงลำดับโดยระบุคอลัมน์ที่ต้องการ โดยใช้ sort_values()
df.groupby('Pclass_Flag').agg({'Age':['median','max']}).reset_index().sort_values(by=('Age', 'median'),ascending=True)
******
ข้อมูลอ้างอิง - https://www.kdnuggets.com/introduction-to-numpy-and-pandas