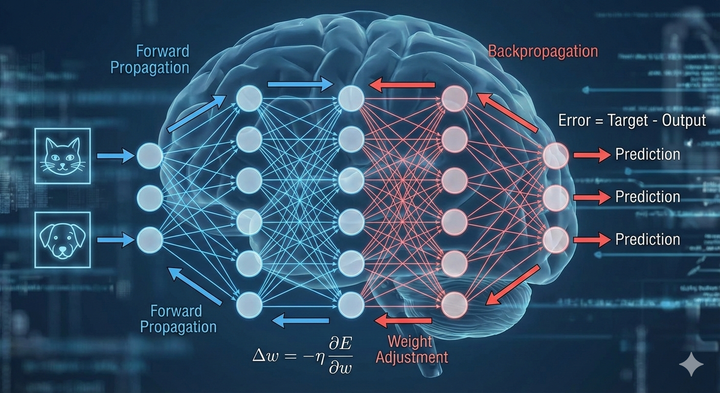
CNN: จากพิกเซลสู่ความเข้าใจ
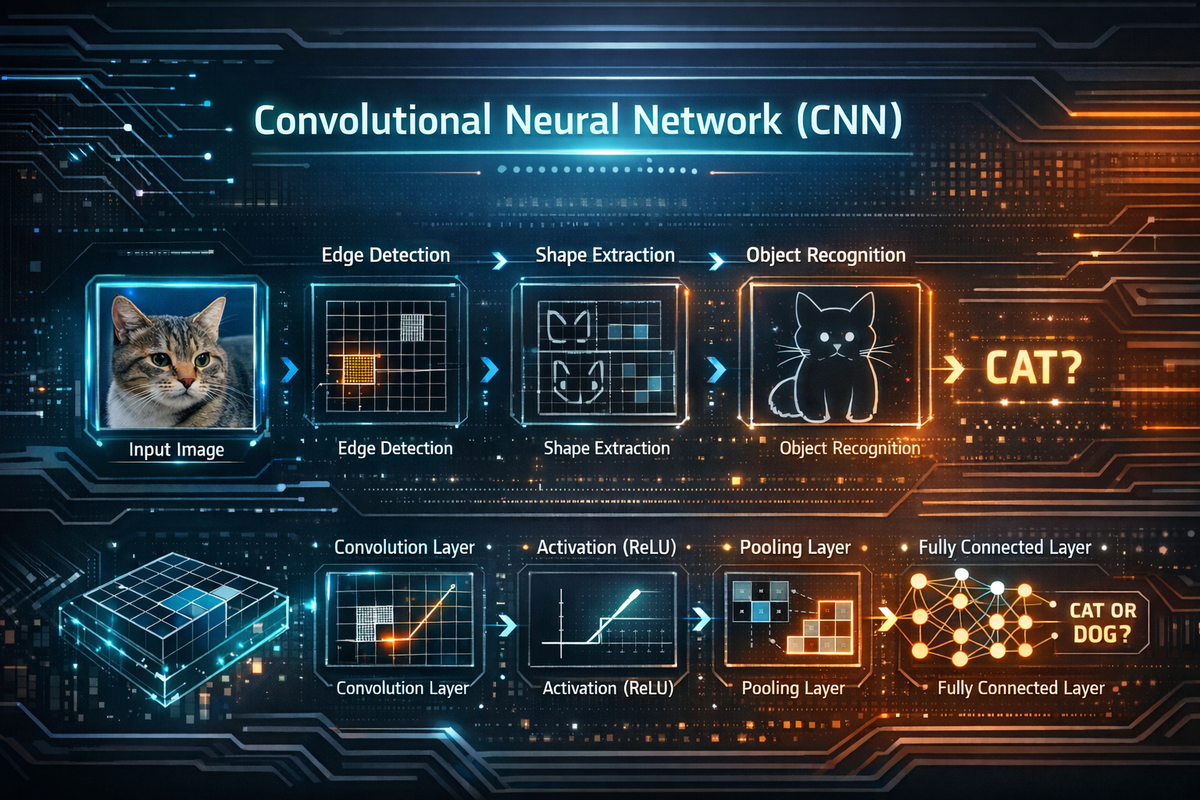
CNN (Convolutional Neural Network) คือโมเดล Deep Learning ที่ออกแบบมาเพื่อ เข้าใจข้อมูลที่เป็นภาพ (Image) โดยเฉพาะ แต่ปัจจุบันยังนำไปใช้กับเสียง วิดีโอ และข้อมูลเชิงพื้นที่อื่น ๆ ได้ด้วย
“สมองที่ค่อย ๆ มองภาพจากรายละเอียดเล็ก ไป ใหญ่”
- มองเส้น (edge)
- มองรูปทรง (shape)
- มองวัตถุ (object)
แทนที่จะดูภาพทั้งภาพพร้อมกันเหมือนมนุษย์
โครงสร้างของ CNN
1) Convolution Layer (แกนหลักของ CNN)
- ใช้ Filter / Kernel (เช่น 3×3)
- เลื่อนสแกนภาพเพื่อจับ pattern
- ตรวจจับ:
- เส้น
- มุม
- ลวดลาย
ผลลัพธ์เรียกว่า Feature Map
2) Activation Function (เช่น ReLU)
- เพิ่มความไม่เป็นเชิงเส้น (Non-linearity)
- ทำให้โมเดลเรียนรู้สิ่งซับซ้อนได้
- ReLU = ติดลบเป็น 0 ติดบวกผ่าน
3) Pooling Layer
- ลดขนาดภาพ
- เก็บข้อมูลสำคัญ
- ทำให้โมเดลทนต่อการขยับเล็กน้อยของภาพ
ตัวอย่างเช่น การทำ Max Pooling
4) Fully Connected Layer
- รวม feature ทั้งหมด
- ใช้ตัดสินใจผลลัพธ์สุดท้ายเช่น “นี่คือแมว หรือ สุนัข”
การทำงาน
ภาพแมว
- CNN ตรวจจับเส้นขอบ
- เรียนรู้รูปหน้า หู ตา
- รวมเป็น “แมว”
CNN ไม่รู้จักคำว่าแมว แต่รู้ว่า pattern แบบนี้ คือ แมว
ทำไม CNN ถึงเก่งเรื่องภาพ
- ใช้ Parameter น้อยกว่า Neural Network ทั่วไป
- เรียนรู้โครงสร้างเชิงพื้นที่ (Spatial)
- ทนต่อ noise และการเปลี่ยนตำแหน่งเล็กน้อย
ตัวอย่างงานที่ใช้ CNN
- Face Recognition
- รถยนต์ไร้คนขับ
- Medical Imaging (X-ray, MRI)
- OCR อ่านลายมือ
- ตรวจจับวัตถุ (Object Detection)
ข้อจำกัด
- ต้องใช้ข้อมูลเยอะ
- ใช้พลังประมวลผลสูง
- อธิบายเหตุผลในการตัดสินใจยาก (Black box)
สรุป
CNN คือ โมเดลที่สอนให้คอมพิวเตอร์ “มองภาพเป็น”